 010 - 86226008
010 - 86226008 483825188@qq.com
483825188@qq.com

基于热扩散核密度确定密度峰值法的历史工况识别
引 言
近年来,随着物联网、大数据和人工智能等技术的兴起,数据驱动的方法在工业智能化的进程中扮演着重要角色。在实际生产过程中,原料性质、生产方案或操作条件等因素的变动将导致生产过程的多模态化[1],如发酵过程[2]、冶金过程和锅炉燃烧过程等,对其过程进行数字化时往往存在着非线性、多模态和变量间的强相关性等问题[3-4]。因此,深入研究多模态过程的特点对实际生产有着重要作用。通过获取历史工况特征,不仅可以为当前装置选择合适的工况模型及参数进行优化,也能为生产决策提供重要的数据参考,如污水处理装置的智能优化、管道泄漏的自动化检测和生产运行状况的有效评估[5-6]等。
在对多模态过程的研究中,由于不同工况间存在着较大的差异,研究者通常假设每种工况下的过程数据近似服从一种高斯分布,运用主成分分析(PCA)、偏最小二乘(PLS)、独立成分分析(ICA)和支持向量数据描述(SVDD)模型等方法提取工况数据的特征,然后建立模型应用于过程故障检测、过程控制和过程优化等[7-10]。由于每种工况下的数据具有相似性,有学者将数据聚类的方法用于多模态过程的特征提取[11]。常用的聚类方法包括模糊C均值法[12]、K-均值法[13]、高斯混合模型(GMM)[14-15]和隐马尔可夫模型(HMM)[16]等,这些方法在获取数据特征时具有一定的有效性,但仍存在一些无法避免的缺陷。如K-均值法需要事先确定聚类数量,对数据中的噪声点敏感;模糊C均值法存在聚类数量和参数选取的问题;HMM模型需要事先知道各种模态的概率且固定不变;GMM模型在使用期望最大法求解时,存在计算量较大、对模型参数的初值敏感和容易陷入局部极值等问题,这些缺点都将导致无法准确地识别工况[17-18]。有学者对GMM模型进行深入研究,提出了给定模型参数初值[19]和基于信息准则确定聚类数量[20]的方法,其中F-J的方法较为著名[21-22],它通过在迭代计算中不断剔除冗余的高斯分量得出聚类结果,但是该方法需要一个较大的聚类数量导致计算量大且收敛困难,其结果的准确性也不能保证。
快速搜索发现密度峰[23](CFSFDP)是基于局部密度的一种聚类技术,它根据聚类中心点密度较大且与其他中心点距离较远的特点,引入高斯核密度估计函数(KDE)计算数据点的密度,再通过欧氏距离计算数据点间的距离,从而完成数据聚类。但是该方法的聚类效果取决于截距参数,为避免这一点,有学者对其进行改进并提出了无须事先确定截距参数的热扩散核密度确定密度峰的技术[24](CFSFDP-HD)。本文提出将CFSFDP-HD技术与GMM模型结合的方法,首先通过CFSFDP-HD方法对多模态过程数据进行聚类,然后将聚类结果作为GMM模型的初值,从而对多模态过程的工况进行较准确的估计。
1 工况识别方法
1.1 高斯混合模型
过程数据 X n×d 是d维的n个样本数据,且
其中,k为高斯模型的数量,τi 和
第i个高斯模型对应的高斯密度函数为:
模型的参数θi 常用EM法[25]求解,通过不断地更新后验概率和模型参数,直到模型参数几乎不变。针对数据
E步骤:
M步骤:
其中,
基于最短信息长度准则的F-J方法只需对
其中,
1.2 热扩散核密度确定密度峰技术
基于热扩散的高斯核函数为:
估算任意样本点i的概率密度函数为:
最佳带宽的选择使用了改进的Sheather–Jones(ISJ)方法[26],其计算步骤如下:
其中,当l ≥ 5时,l的取值对
带宽t的详细求解步骤如下:
(1)设置一个较小的容差ε = 10-9,令yq=ε,q = 0;
(2)计算
(3)如果
计算每一样本点i到最近的高密度点j的距离:
1.3 提出方法的计算步骤
本文提出的方法对近似服从高斯分布的未知多模态稳态工况进行识别时,首先利用CFSFDP-HD技术对多模态过程数据进行聚类,确定聚类中心点及其个数(即工况个数),然后将每一类数据的平均值和协方差作为GMM模型的初值,迭代求出不同工况的特征参数。其计算过程如下:
(1)将数据标准化处理,求取参数αk;
(2)由参数αk 和式(11)~
(3)由
(4)将每一类的特征参数作为GMM模型初值,求出最终工况参数。
通过以上步骤即可完成对历史工况的准确识别,下面通过第2节中的两个例子对该方法进行验证。
图1
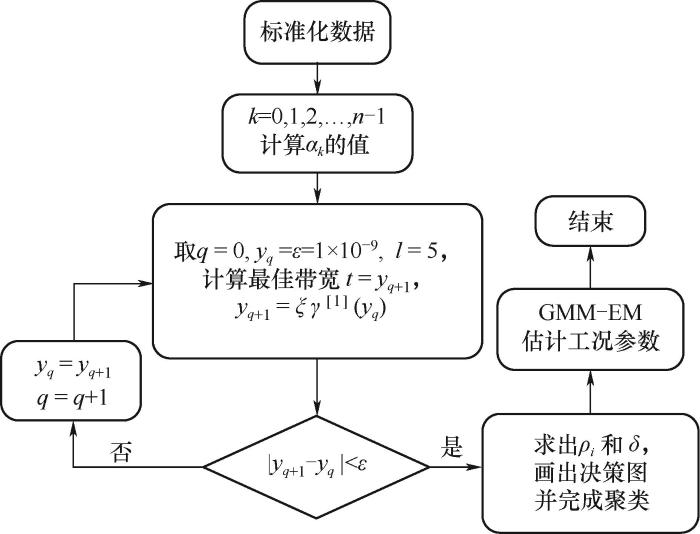
图1 基于热扩散核密度的工况识别方法流程图
Fig.1 Flow chart of recognizing operating modes based on kernel density estimation of heat diffusion


