 010 - 86226008
010 - 86226008 483825188@qq.com
483825188@qq.com

基于分子指纹和拓扑指数的工质临界温度理论预测
引 言
临界温度(Tc)作为工质能维持液相的最高温度,是建立状态方程的基础,也可以用于计算工质其他物性如焓、熵、比热容、黏度、热导率等。同时,临界温度是超临界萃取过程中的重要参数。因此,获取工质准确的临界温度具有重要的科学意义和工程价值[1-5]。实验是获取临界温度最有效的方式。然而由于实验研究代价高昂、复杂性高,无法仅依靠实验手段获得工质的临界温度。因此,有必要提出一种能够准确预测工质临界温度的理论模型。
临界温度的预测方法主要包括经验公式法、状态方程法和定量结构-性质关系法(quantitative structure-property relationship, QSPR)。经验公式法采用一些易于测量的参数,如沸点、密度等,建立相应的关联式得到临界温度。Reid等[6]最早提出了临界温度与沸点的关联式Tc=1.5Tb。周传光等[7]基于沸点与对比密度,提出了部分化合物临界温度的关联式,平均偏差为1.35%。王新红等[8]以沸点、对比密度、相对分子质量为参数,提出了一个新的有机物临界温度计算模型,平均偏差为2.36%。经验公式法形式简单、计算精度较高,但缺乏理论基础。状态方程法可以基于pVT数据,拟合获得工质状态方程中相应参数,而后反推得到物质的临界温度。例如,Kontogeorgis等[9]采用状态方程法估算了6种烷烃的Tc,绝对平均偏差均在2%以内。Hsieh等[10]依据同样的思路,首先获得Peng-Robinson(PR)状态方程的参数,进而得到392种纯物质的临界温度,平均偏差为5.4%。状态方程法需要已知工质pVT数据,且计算流程复杂,适用于密度数据较为丰富的物质。定量结构-性质关系法(QSPR)根据分子结构-物质性质之间的构效关系,对物质相关性质进行建模和预测。基团贡献法是QSPR中最常用的一种方法,包括经典的Lydersen法[11]、Joback法[12]等。这些方法假设分子性质为各基团贡献的线性加和,而基团贡献度在不同分子中保持不变。这种线性加和的方法使用较方便,但没有考虑不同基团的位置信息,导致该方法不能有效区分同分异构体。尽管后续的一些方法如Constantinou-Gani法[13]、Marrero-Pardillo法[14]等,通过引入多级基团和键贡献在一定程度上缓解了上述缺陷,但适用范围依然有限。综合分析以上方法可知,现有模型无法对常见工质进行准确估算,须采用新的思路,以实现对包括同分异构体工质在内的常见工质临界温度的精准预测。
分子结构描述符[如分子指纹(molecular fingerprints, MF)[15]、拓扑指数(topological index, TI)[16]等]作为一种将分子结构编码为结构化数据的方法,可以将一种物质与其他物质进行明确区分。将分子描述符的概念引入QSPR模型,有望解决工质同分异构体的区分问题。在实际使用中,分子描述符通常与机器学习方法(machine learning, ML)相结合,以构建物质特性预测模型[17-19]。近年来,随着计算机性能的不断提高,有学者将分子描述符和机器学习应用于工质物性[20-24]的预测,预测效果良好。
本研究受上述分子描述符工作的启发,首先以分子指纹表征分子结构,并借助机器学习算法建立16种临界温度的QSPR预测模型。此外,为了进一步提升本文模型的预测精度,本研究还将分子指纹与拓扑指数相结合,得到新的MF+TI-ML模型(以分子指纹和拓扑指数表达分子结构,结合机器学习算法建立模型),以期取得良好的预测效果。
1 方 法
1.1 数据库的搭建
本研究中工质的临界温度实验数据取自物理性质设计研究所(DIPPR®801)[25]及相关文献[26]。根据实验数据不确定度对其进行筛选后,获得了155种工质的Tc (本文所涉及工质的详细信息,参见文末附录)。搭建的数据库中,临界温度的范围分布在190.56~583.00 K。数据库中工质可分为五种:烷烃、烯烃、卤代烷烃、卤代烯烃、醚类。为提升模型泛化能力,从每种类型工质中选取其中70%的数据点进入训练集,剩下的30%作为测试集。训练集用于建立工质临界温度的模型,测试集用于评估模型的预测性能。
1.2 分子指纹的生成
通过ChemDraw程序获得工质分子的线性输入规范(simplified molecular input line entry system, SMILES),随后利用在线转换工具ChemDes [27]将SMILES字符串转换为相同长度的二进制位串(即分子指纹)。为了研究不同长度/类型的指纹对QSPR模型性能的影响,本文选择了计算四种分子指纹,包括两种Key型指纹:MACCS(166位)和Pubchem(881位),一种Path型指纹:Extended(1024位)和一种Circular型指纹:Morgan(2048位)。
1.3 回归算法的选择
本文使用了四种机器学习算法,包括支持向量回归(support vector regression, SVR)、回归树(regression tree, RT)、随机森林(random forest, RF)以及多层感知机(multi-layer perceptron, MLP)。
支持向量回归通过核技巧将非线性数据映射到高维空间中,将非线性关系转换为线性的形式,其精度取决于参数的选择,例如核函数、宽度系数γ、不敏感损失系数ε、惩罚系数C等[28]。在本文中,将采用5折交叉验证和网格搜索确定参数的最佳组合。决策树(decision tree, DT)利用多节点的树结构来描述各变量与目标之间的非线性关系,回归树是决策树的回归版本。由于树模型具有较高的方差,可能导致结果不稳定,基于树模型的集成学习算法随机森林相对树模型有较大的改进[29],在物性预测中应用较多。人工神经网络(artificial neural network, ANN)模拟神经系统的结构,通过不断调整神经元间的权重和偏差,使整个网络能更好地拟合数据[30-34]。多层感知机(MLP)是一种前馈神经网络,通过相互连接的人工神经元和复杂的拓扑结构来模拟非线性关系[35]。本文利用深度学习库Keras搭建了具有双隐层的MLP,并通过试错法确定了神经元数、激活函数、学习率的最优组合。
1.4 评估指标的选择
本文选用均方根偏差(RMSE)、绝对平均偏差(AAD)、决定系数(R2)评估模型的预测性能, 相关定义式如下。
式中,m表示样本个数;
2 实验结果与讨论
2.1 模型的建立与评估
将四种分子指纹(MACCS、Pubchem、Extended、Morgan)分别用作四种机器学习算法(SVR、RT、RF、MLP)的输入特征,得到16种临界温度的QSPR模型。各模型在测试集中的预测性能(以绝对平均偏差AAD为评价指标)如图1所示。
图1
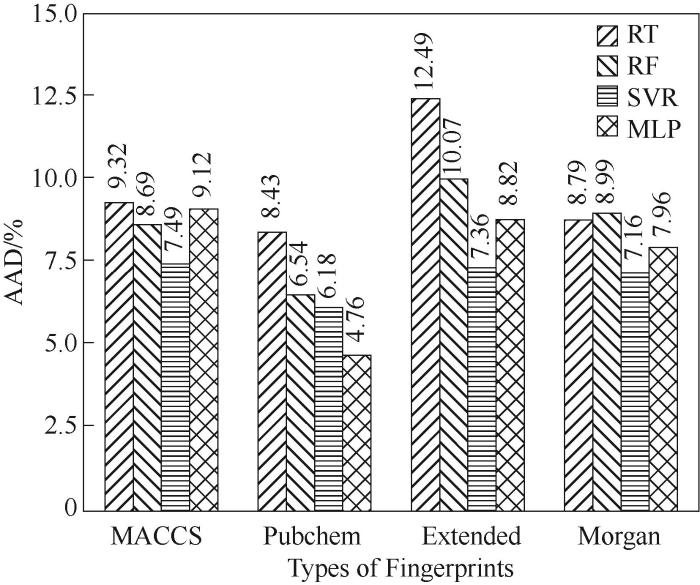
图1 以不同指纹为输入的各QSPR模型的预测精度
Fig.1 Prediction accuracy of QSPR models with different fingerprints as inputs


